
It’s been a while since my last post. Getting married, honeymooning, buying a house, etc. took away the time I had for this. But all of that is nearing it’s end, so I’m getting back into the regular cadence of working on the scraping project. Since I’m now back into it, and got everything up and running, I figured the most sensible place to start is the architecture that has been implemented.
The Problem:
The most sensible place to start any discussions of architecture is clearly stating what the system is supposed to do. I need a system that accomplishes these three things.
- I need a system that is able to reliably scrape data from any website or consume data from any source.
- I need a place where this data can be loaded and reported on in a cohesive format.
- I need the product to be lightweight as far as storage space required and CPU so I don’t have to pay out the wazoo.
Overview:
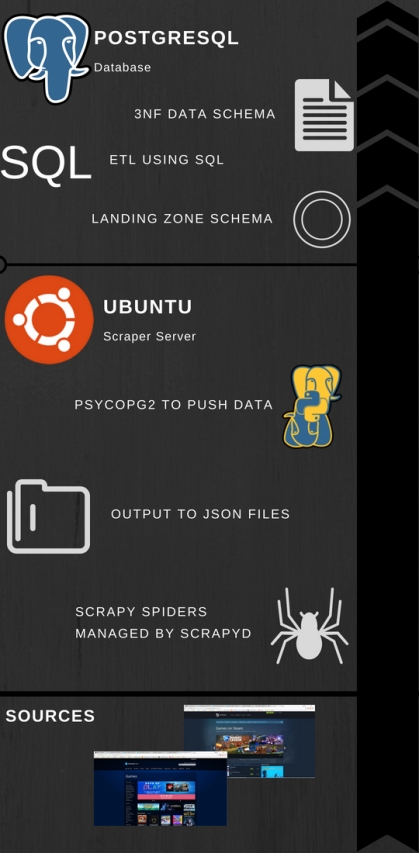
Overview of the architecture, from inputs to database inserts.
In order to meet this, a straightforward architecture was implemented. Using Amazon Web Services both a EC2 instance and RDS instance were set up, with the EC2 being an Ubuntu instance and the RDS being Postgresql. In sequential order, here is how the scraper works.
- Using python’s Scrapy library, we’ve written Scrapy projects which look to specific sources to bring in data based upon the HTML on websites. Right now, we’ve targeted two, but can expand to as many as needed. These Scrapy spiders are scheduled through Scrapyd, a framework that no only allows for scheduling and management of spiders, but also offers better performance by operating on Twistd making it asynchronous.
- As the spiders are constantly running they are outputting to JSON files on the server. Basically, the driver here is to have a place to drop the output of the data onto the server so that data won’t be lost if something happens with one of the processes.
- A Python class was written with Psycopg2 in a way that is meant to be extensible for future data sources. The idea being, that as the data model and data sources are changed/expanded upon, the only thing that will need to change is the class itself. None of the scripts that call the class to insert data from our existing data sources will need to change.
- A staging area was created within the RDS PostgreSQL instance which ingests the raw data from the data source. Where possible, a unique index was created that checks for changes before accepting the data into the staging area. As we have scrapers hitting sources repeatedly, we are going to be grabbing the same data. What we’re interested in are the changes, especially in regards to new items or price changes. Also, we want to make as efficient as possible of a architecture so storing only the data we are interested in just makes sense.
- Once data has been accepted into the landing zone, the Ubuntu instance is used to schedule a slew of ETL jobs written in SQL and passed to PostgreSQL for execution using Psycopg2. Postgresql doesn’t have a native scheduler readily available, so we use the Crontab functionality of Ubuntu to execute a script for each of our sources that calls from a class containing all of our ETL functions. The end result of this is a 3NF model populated with data and appropriate relationships made.
So, it’s now up and running, and data is flowing through into the objects. The data is populating for all tables where it is expected and I could begin reporting price changes today. The best part? All of this was built using $0’s of infrastructure from Amazon Web Services (and a lot of my time). I’m running out of storage space rapidly (20 gigs from the free tier ran out over a couple days), and the CPU is not beefy at all, so stalls out if more than one scraper is running at a time (as pictured below).
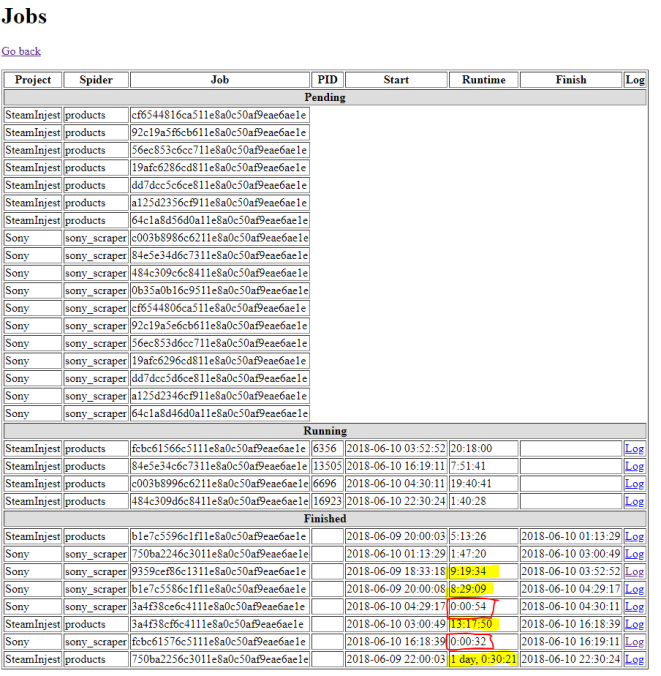
Performance goes down dramatically in yellow. In red, my scraper has been blocked from accessing the site (which didn’t happen before refactor…I’ll go into that another time)
To refer back to the original goal, I would say it has been achieved. Not to say that it couldn’t be improved upon and optimized. But overall, the first serious foray into scraping seems to of gone well. Feel free to reach out with any questions, or suggestions!
